Recently the topic of LLM-assisted development or “vibe coding” has become nearly unavoidable. Thanks to tools like Cursor and Claude Code, it’s now easier than ever to make code of questionable quality on a massive scale. Entire companies are basing their futures on this development model working out. I want to discuss what, if anything, LLMs have to offer programmers while also highlighting the cracks that are beginning to form.
To keep the scope limited, I won’t be discussing the ethical or environmental concerns with AI use here, although those are massively important topics in their own right.
My Use of AI
For the sake of impartiality, I think it’s necessary to state how I use AI for my development work. I do use Claude for menial tasks and boilerplate, but anything it generates I will manually edit and check for correctness, the same as if I was reviewing code from anything else. I don’t, and don’t ever plan to use, LLM-integrated IDEs.
Move Fast, Break Things Faster
Undoubtedly, the most common thing that vibe coders will cite as their major advantage is the speed at which they are able to generate code with LLMs, and it’s true; LLMs can generate much faster than a human can type. However, every coin has three two sides.
Code Churn
You may ask for one change, and in response, it will reformat your entire file, add new comments, change code style, maybe even try to “optimise” logic. The result is, commits that should be atomic and easily understandable become bloated 100+ line diffs with a bunch of unnecessary clutter that has nothing to do with the core change. Reviewing code changes of that size is tricky, especially in languages like C or C++ where a single character can massively alter what a line of code actually does.
In essence, LLMs create code churn like you’d never believe, and it makes it practically impossible to know what your own code does, or to keep track of changes. It also creates countless opportunities for introducing new bugs, crashes, and security vulnerabilities. This to me is the central problem with current “vibe coding” approaches: an ever-shifting quicksand codebase that disintegrates just as fast as you prompt a new feature. (SLOP!)
Reliability
You may be thinking “What’s so wrong with code churn?”, well it means you can’t trust any of your codebase to be reliable. If nothing sticks for longer than a few commits, how can you trust that it works properly? Reliability is something that LLM-generated codebases suffer massively from. Take for example… Claude.
Anthropic’s developers proudly advertise their “dogfooding” approach to Claude Code, in essence, they use the product to build the product. Usually, this is a very smart thing to do, as it forces your developers to actually engage with the user experience; the user’s problems also become the dev’s problems and there’s more of an incentive to fix them. In the case of LLMs, however, this is kind of a self-fulfilling prophecy.
Coincidentally, Claude’s website suffers from some of the worst uptime scores I’ve ever seen for a corporate product with this level of funding.

Ouch.
For reference, the reliability “gold-standard” is the “five nines” or 99.999% uptime, giving you about 5 minutes of downtime a year. While many services fail to reach this standard, Claude has dipped into 98% at time of writing. On top of that, on March 31, 2026, Anthropic accidentally included a JavaScript sourcemap for Claude Code, in essence, leaking all 512,000 lines (yes that many) of TypeScript.
Dogfooding does not appear to be going well for them.
Reasoning
The second most fundamental issue is a limitation of LLMs themselves. No matter how many parameters you shove into a large language model, it will never be capable of reasoning. They just aren’t built for that. Despite what the Reason or Think buttons that Claude and ChatGPT have incorporated in recent revisions would have you believe, LLMs cannot come up with an original idea nor reason about a problem logically. Their output is, in some way, a predetermined amalgamation of their training data.
For many problems, this can be sufficient. Assuming you don’t care about potential license violations, chances are someone else has already done the thing you’re trying to do, and LLMs can be helpful to short-circuit you to an existing solution. If, however, you are working on a project with sparse documentation, or with relatively few examples to draw upon they really begin to struggle.
A Case Study: Recompilation
Recompilations are a fairly new technique for porting a game from one platform to another, pioneered by Sonic Unleashed Recompiled, which I’ve contributed to, and Zelda 64: Recompiled. Both of these projects are built on a fairly generic, console-level framework which can be extended with some elbow grease to work for similar games. Since much of the hard part was already established by those two projects for Xbox 360 and N64 games respectively, there has been a massive wave of recompilation efforts based on those projects.
Many of them have been AI generated.
Preface:
While I do not like these projects, that isn’t a license to harass these projects or their leads. Please be respectful.
Shortly after we started Marathon Recompiled, the repo was forked for LibertyRecomp, an attempt at a GTA IV recompilation. It immediately became clear, that it was vibe coded. Recompilation, being a pretty new and obscure technique, is not something that models have much information on, their training data is almost always months old at the least. The repository was inundated with nonsense commits and hallucinations that to someone versed in the technique, seemed like gibberish.
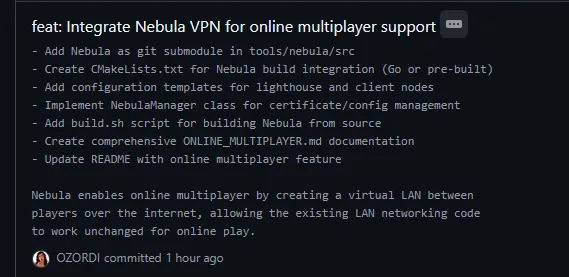
Prior to the game booting, a commit was made to add support for a VPN for online play.
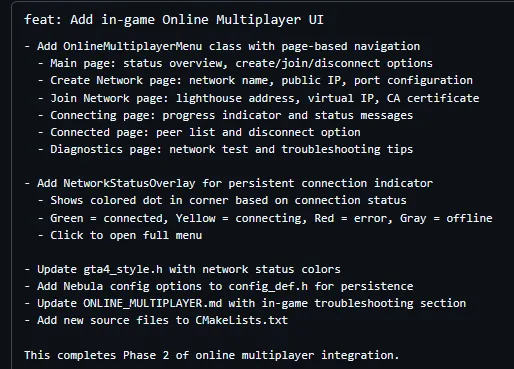
A reminder, the game does not boot yet.
Every change was massive, unnecessary and did little to advance the actual project. LibertyRecomp is far from the only instance. There’s also:
- Wave-Race-64-recomp
- SanRecomp (from the same guy as LibertyRecomp)
and UnleashedRecomp_Android, which is attempting to bring the existing Unleashed Recomp to Android devices. That repo has, at time of writing, 1,045 added commits. Since forking from the source repository, the commit messages mention a “fix” 1,106 times. That’s fixes by LLMs for stuff exclusively added by LLMs.
GIGO
As much as I dislike terms like “prompt engineering”, there is a grain of truth. If you don’t know what the solution should look like, or how to write good code unassisted, you’re never going to get there with LLMs. Because they lack reasoning, you, the user, must supply it. Without human intuition an LLM is just going to keep spitting out the next most-likely bit of code.
In the case of something complicated like recompilation or emulation, if you don’t know enough about the topic yourself, you’re never going to be able to direct an LLM to produce a coherent and logical output. Even if you are familiar, I’ve found in a lot of cases that trying to direct an LLM takes just as long, if not longer than writing it myself.
By using an LLM to produce code in an area you don’t understand, you’re both writing bad code, and robbing yourself of a potential learning opportunity. It’s only through thinking, trying, failing, and remaking that you learn how to design efficient systems. Typing a prompt, copy + pasting, building ad infinitum will never teach you anything.
Conclusion
While I have presented an overall negative view of LLMs here, I do not think they are useless, rather they are easily abusable and are designed to encourage laziness and abuse. There is certainly much more to be said about this issue, and for better or for worse, I don’t see LLMs going away any time soon.
If you’re a “vibe coder” take a break from the prompts, and try to learn some techniques on your own. Tone down the loud and rather irritating “adapt or die” rhetoric. You may find there is still value in learning the “old ways”.